作者通过CNN提取特征 + SVM分类器 + 逻辑回归确定区域,做目标检测。
Rich feature hierarchies for accurate object detection and semantic segmentation
传统目标检测基本都是特征工程,通过low-level feature,各种methods做ensemble。这篇文章将CNN和目标检测结合在一起,提出了R-CNN(Regions with CNN features)。
作者提出的方法,主要包括三个模块:1、region proposal,2、CNN提取特征,3、特征分类。如下图所示:
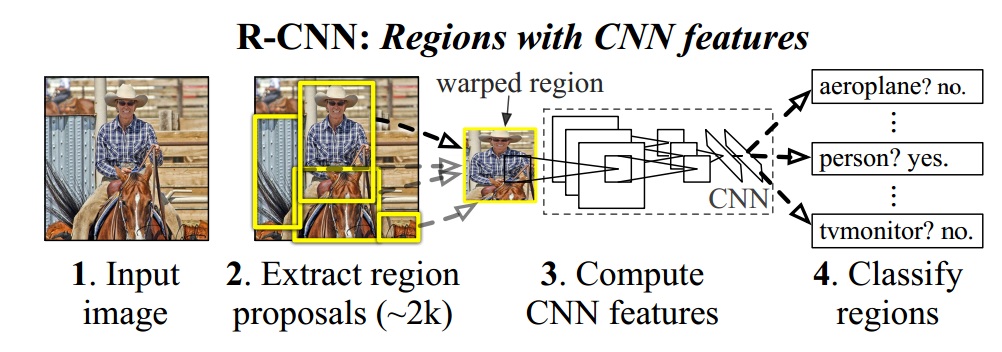
Region proposal
Region proposal是用来做目标定位,即定位目标在图像中的位置。算法有很多种,作者使用的是selective search。region在图像中的位置可以表示为$P=(P_x, P_y, P_w, P_h)$
CNN输入图像的size都是固定大小的,region区域size可能不符合CNN对输入要求,这时要wrap image。
CNN提取特征
CNN网络使用了AlexNet,输入为224
x224。特征用的是最后一个全连接层的输出,4096维的向量。
因为标记样本稀缺,作者首先在大的数据集(ImageNet)进行pre-training,之后再在小的数据集(PASCAL)上fine-tuning,这样可以提升准确率。
网络第一层都是在学习边缘和颜色等信息,后面层学到的信息难以可视化。但是可以通过判断激活值的大小,确定输入哪些区域能“激活”feature map的值。最后一个pooling层的输出为6x6x256=9216。每个激活值对应到输入上的区域是195x195。下图每一行是每一类别,top 16激活值对应的region。

白色框为received field,数值为对应的激活值。可以看出每一列学到的特征类似。
分类
这一部分其实包括两个部分,确定类别以及确定region。
确定类别
通过feature来判断类别,作者训练的是binary linear SVM,即one-to-rest。
判断一个region是否包含目标时,作者使用了greedy non-maximum suppression,如果intersection-over-union(IoU) overlap的分值高于阈值,那么判断包含目标,否则作为负样本。
确定区域
对区域进行回归。输入$(P^i, G^i)$,这里$P^i=(P^i_x, P^i_y, P^i_w, P^i_h)$是候选的region, $G = (G_x, G_y, G_w, G_h)$是标记正确的region。学习的目的是把proposed box $P$映射到真实region$G$,前两个参数是位置坐标,即region的中心,图像缩放,中心的不变;后两个是width和height,映射到log空间,预测真实region$\hat G$
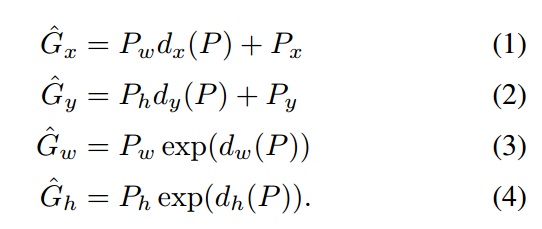
这里的$d_*(P)$是最后一个pool层输出特征的线性函数。
总结
作者提出算法在PASCAL VOC 2012上有30%提升。取得这样的效果主要在于两点:1、使用CNN提取特征。2、在样本稀缺时,先通过在ImageNet上pre-training,在在小样本集上fine-tuning。